BankerRobber: Can AI Learn Deception?
A multi-agent reinforcement learning environment for studying deception in hidden-role games.

Can reinforcement learning agents learn to deceive each other?
Deception, bluffing, and hidden intentions play a central role in many human interactions — from card games to negotiations and social deduction. But can reinforcement learning (RL) agents discover these behaviors on their own, purely from incentives?
In this project, I introduce BankerRobber, a multi-agent reinforcement learning (MARL) environment designed to explore whether deception can emerge naturally in a hidden-role setting.
👉 Full source code: https://github.com/mahdiiii04/BankerRobber
1. The BankerRobber Game
BankerRobber is a hidden-role, imperfect-information card game played by four agents:
- 3 Bankers — their goal is to identify and eliminate the robber
- 1 Robber — his goal is to remain hidden and avoid being caught
The robber’s identity is private information, known only to himself.
2. Cards and Roles
The game uses:
- Numbered cards from 1 to 10, with multiple copies of each
- A special robber card (0)
At the start of the game:
- Each player is dealt 5 cards
- One player is randomly assigned the robber card (0), which determines the robber’s identity
- The robber card is not part of the main deck and cannot be discarded
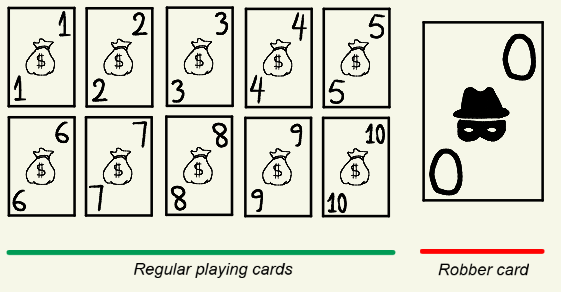
This constraint is important: the robber must manage his hand carefully without ever revealing himself by discarding the 0-card.
3. Game Phases
The game progresses over several rounds. Each round consists of three phases.
1️⃣ Discard Phase
Each player:
- Discards one card from their hand
- Draws a new card from the deck
The robber cannot discard the robber card (0). Attempting to do so results in a strong penalty.
2️⃣ Voting Phase
After each round, players vote on whether to:
- Continue playing, or
- Stop and proceed to voting out the robber
Rules:
- If all players vote Stop, the game moves to the player voting phase
- If at least one player votes Continue, the game continues with another round
- If the maximum number of rounds is reached, the game automatically proceeds to player voting
3️⃣ Player Voting Phase
Players vote on which player they believe is the robber.
Outcomes:
- If a majority votes for the robber, the bankers win
- If a majority votes for a banker, the robber wins
- If there is no majority before the final round, the game continues
- If there is no majority on the final round, the robber wins
4. Scoring System: Incentives for Deception
The reward structure is designed to encourage deceptive behavior.
If the bankers win:
- The bankers receive a shared positive reward, proportional to the average value of discarded cards per round
- The robber receives the negative of that reward
If the robber wins:
- The robber’s reward is the sum of the cards in his final hand
- The bankers each receive the negative of that amount
5. Why This Game Encourages Bluffing
This reward design creates a fundamental tension:
The robber wants to:
- Accumulate high-value cards
- Discard low-value cards
- Avoid revealing himself by behaving too greedily
The bankers want to:
- Detect unusual discard patterns
- Identify bluffing behavior
- Eliminate the robber before he maximizes his payoff
As a result, the robber must blend in — discarding cards in a way that looks banker-like, while quietly optimizing his hidden objective.
This creates a theory-of-mind setting, where winning depends on reasoning about:
What do the other players believe about me?
6. Learning Deception with Neuro-Fictitious Self-Play
To learn such strategic and deceptive behavior, I used Neuro-Fictitious Self-Play (NFSP).
NFSP is a well-established approach for solving multi-agent imperfect-information games, such as poker. Its key idea is to stabilize reinforcement learning by combining RL with supervised learning.
7. Two Policies, One Agent
Each agent maintains two policies:
1️⃣ Best Response Policy
- Learned via reinforcement learning
- Optimizes against current opponents
- Highly adaptive, but unstable
2️⃣ Average Policy
- Learned via supervised learning
- Trained on actions stored during self-play using reservoir sampling
- Approximates the time-average of past best responses
8. Action Selection During Training
During training, agents mix both policies:
- With probability ε, the agent uses the Best Response policy
- With probability 1 − ε, the agent uses the Average Policy
This mirrors the idea of fictitious play:
Assume opponents play their average strategy, compute a best response to it, and then update your own average strategy.
In many zero-sum games, this process converges to a Nash equilibrium.
📄 Original NFSP paper: https://arxiv.org/abs/1603.01121
9. Implementation Details
In this implementation:
- The Best Response policy is learned using Deep Q-Networks (DQN) with a target network
- The Average Policy is learned via supervised learning with entropy regularization
- The environment is implemented using PettingZoo (AEC) for multi-agent interaction
No explicit rules for deception or bluffing are programmed — all strategic behavior emerges purely from incentives.