Nice Chickens: How Can Empathy Affect Decision-Making in AI?
A MARL / GT experiment introducing engineered empathy as a reward.

What if RL agents could care about each other?
The Hawk–Dove (Chicken) game is a classic dilemma in game theory: players must choose between cooperation (Dove) and defection (Hawk). In the standard two-player setting, the game admits well-known Nash equilibria depending on the relationship between the reward of winning (V) and the cost of conflict (C).
In this project, I explore a different question:
What happens if we explicitly engineer empathy into the reward function of reinforcement learning agents?
To study this, I designed a population-based, iterated variant of the Hawk–Dove game, and augmented its reward with a mathematical formulation of empathy. The result was not what I initially expected.
The Game: A Population-Based Chicken Variant
The environment is an iterated, population-based version of the Chicken game:
- At each time step (“day”), every agent is randomly assigned to a resource.
- Each resource can host at most two agents.
- If two agents meet at the same resource, they simultaneously choose to cooperate (D) or defect (H), producing standard Chicken-game outcomes.
- If an agent is assigned alone to a resource, it receives the full prize uncontested.
Note: The number of resources is always ≥ number of agents / 2, and assignment stops once a resource already contains two agents. Therefore, no other interaction patterns are possible.
The full source code, trained models, and usage guide are available here: 👉 https://github.com/mahdiiii04/NiceChickens
Baseline: Hawk–Dove Payoff Structure
The original Hawk–Dove payoff matrix is:
| Dove | Hawk | |
|---|---|---|
| Dove | V/2 , V/2 | 0 , V |
| Hawk | V , 0 | (V−C)/2 , (V−C)/2 |
From classical game theory:
- When V > C, Hawk (defection) dominates.
- Otherwise, the game admits a mixed Nash equilibrium, where players cooperate with probability p.
- At the boundary, both Hawks and Doves coexist in the population.
Engineering Empathy into the Reward
I redefine the agent’s reward as a combination of self-interest and empathy-driven terms:
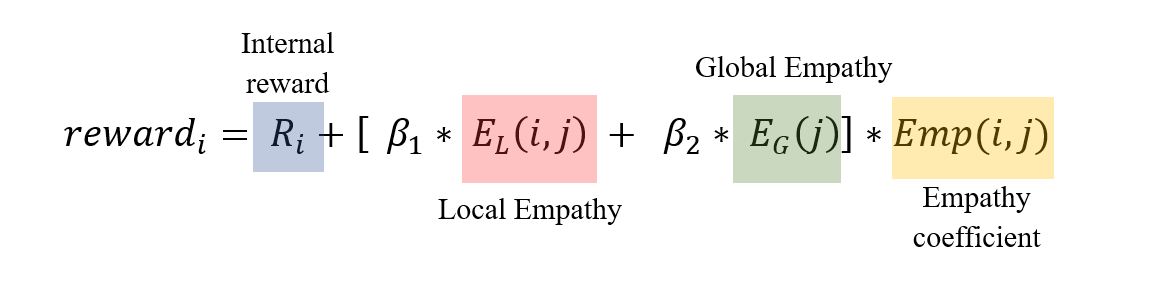
Let’s unpack this step by step.
1. Internal Reward
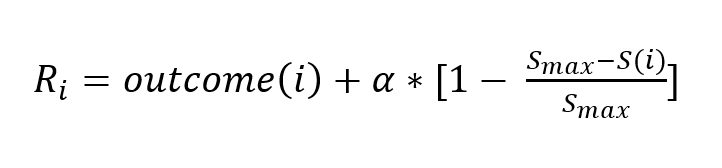
This component includes:
- The original game payoff.
- An additional progress term reflecting how close the agent is to winning the game.
Here:
- $S(i)$ is the agent’s current score
- $S_{max}$ is the score required to win
- $\alpha$ controls the weight of progress toward winning
In the experiments below, $(\alpha = 0)$ to isolate the effect of empathy alone.
2. Local Empathy
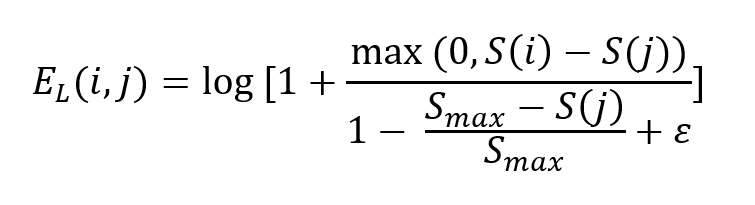
Local empathy captures how much an agent empathizes with its current opponent.
- It depends on the score difference between the agent and its opponent.
- It is normalized by how close the opponent is to winning.
This formulation encourages stronger empathy toward low-scoring, struggling opponents.
The strength of this term is controlled by $\beta_1$.
3. Global Empathy
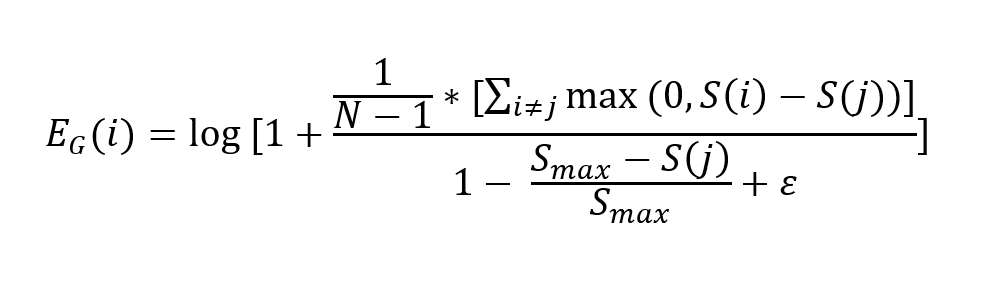
Global empathy measures how poorly the opponent is doing relative to the entire population.
- If both matched agents are doing well compared to others, empathy should be lower.
- If the opponent is lagging behind the population, empathy should be higher.
This term depends on the average score difference between the opponent and all other agents, again normalized by distance to winning.
The strength of this term is controlled by $\beta_2$.
4. Empathy Coefficient
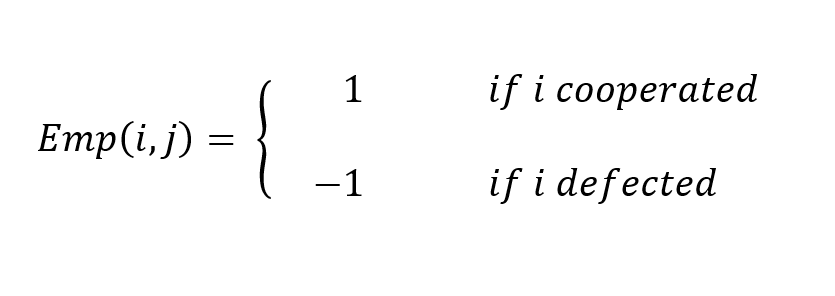
This term determines how empathy is applied:
- Positive when the agent cooperates → empathy becomes a reward.
- Negative when the agent defects → empathy becomes a penalty.
In short: cooperating with a struggling opponent feels good ; exploiting them feels bad.
Experiments
Training Setup
- Algorithm: Centralized PPO (shared policy)
- Library: Stable-Baselines3
- Agents: 6
- Training: 1M timesteps per configuration
Parameters:
- $S_{max} = 100$
- $V = 10$
- $C = 2$
- $\alpha = 0$
Each trained model is evaluated over 200 episodes.
All trained models are available in the ./models directory of the repository.
1. No Empathy vs Empathy
Comparison:
- No empathy: $\beta_1 = \beta_2 = 0$
- Empathy enabled: $\beta_1 = \beta_2 = 1$
Episode Length
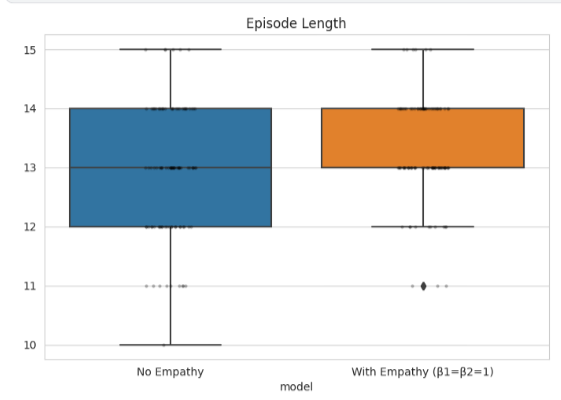
Episodes last longer with empathy, indicating sustained interaction and slower convergence to a winner.
Average Score
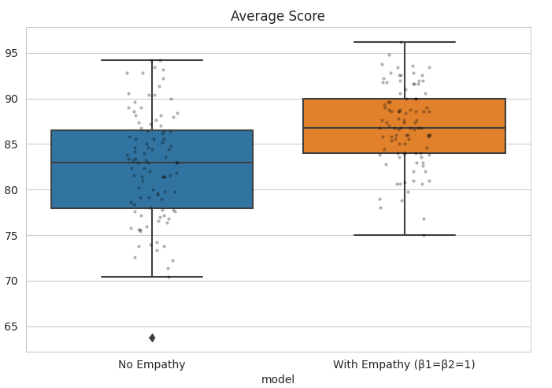
The average score increases from ~83 to ~87, with a tighter distribution.
Inequality (Gini Coefficient)
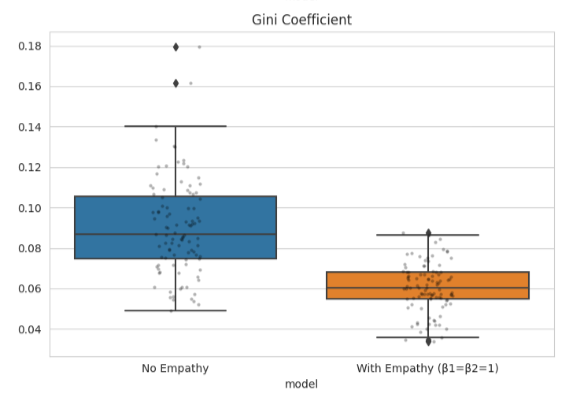
Inequality drops sharply from ~0.09 to ~0.06, suggesting a more balanced population.
Score Trajectories
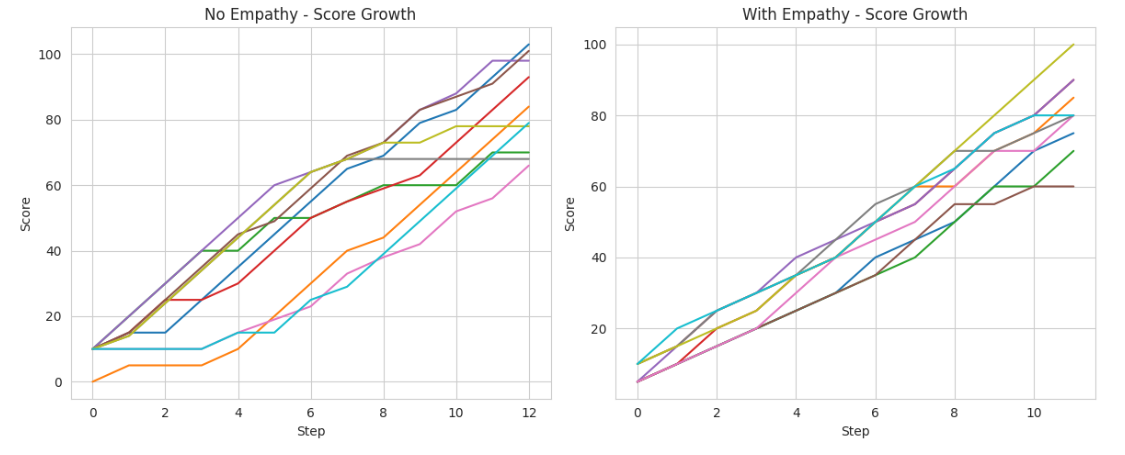
With empathy, scores remain tightly clustered throughout most of the game and only diverge near the end. Without empathy, separation appears almost immediately.
Cooperation Rate Over Time
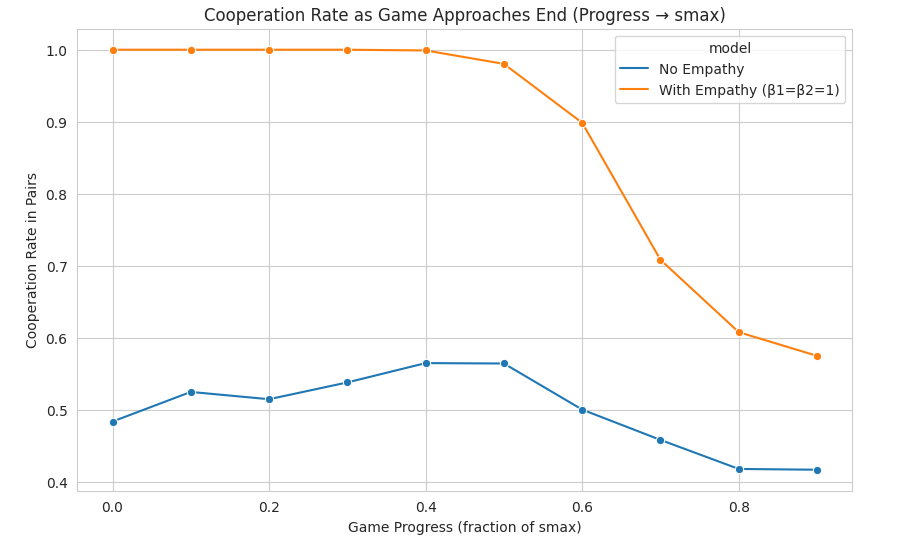
- Without empathy: cooperation fluctuates around ~0.5, consistent with population-based Chicken dynamics even when (V > C).
- With empathy: near-universal early cooperation emerges, followed by a sharp collapse into defection, settling around ~0.6 near $S_{max}$.
What’s really happening?
- Agents did not become altruistic.
- Instead, they exploited the reward design.
- Early cooperation keeps scores low and equal, maximizing future empathy bonuses.
- Near the end, agents discover that defection is the fastest path to victory.
Empathy was not internalized—it was optimized against.
2. Varying the Strength of Empathy
Here: \(\beta_1 = \beta_2 \in \{0, 1, 2.5, 5, 10, 25\}\)
Average Score
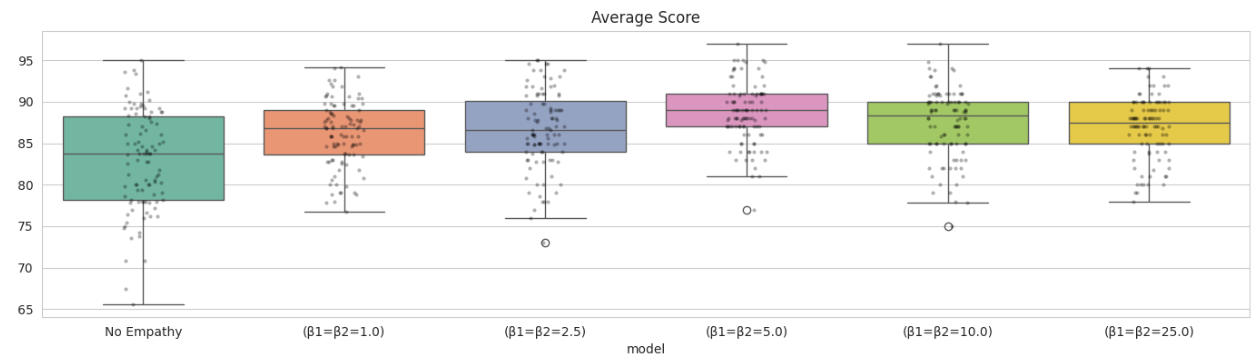
Average performance peaks around $\beta = 5$ (~89), forming an inverted-U curve.
Inequality
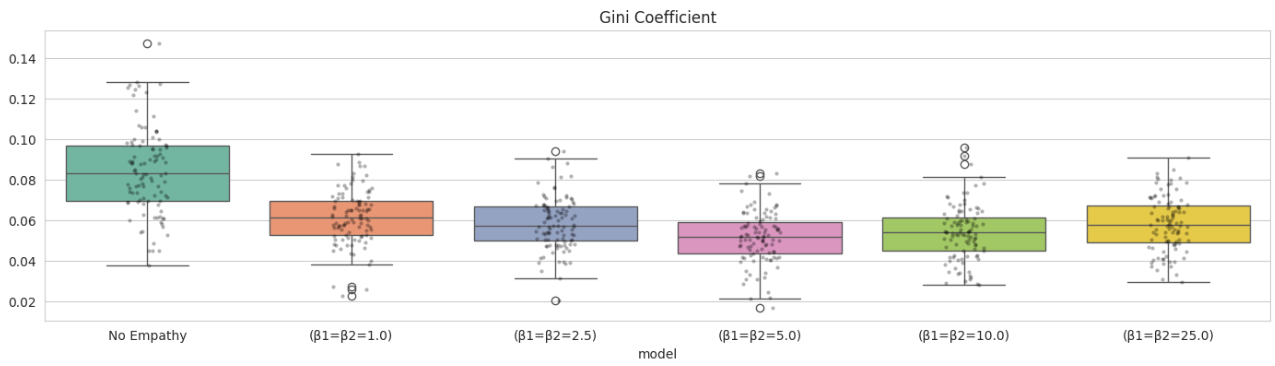
Inequality is minimized near $\beta = 5$ (~0.05), forming a U-shaped curve.
Takeaway: Empathy improves outcomes—but too much of it becomes counterproductive.
3. Local vs Global Empathy
We now compare:
- No empathy
- Local empathy only $(\beta_1 = 1, \beta_2 = 0)$
- Global empathy only $(\beta_1 = 0, \beta_2 = 1)$
| Average Scores | Gini Coefficients |
|---|---|
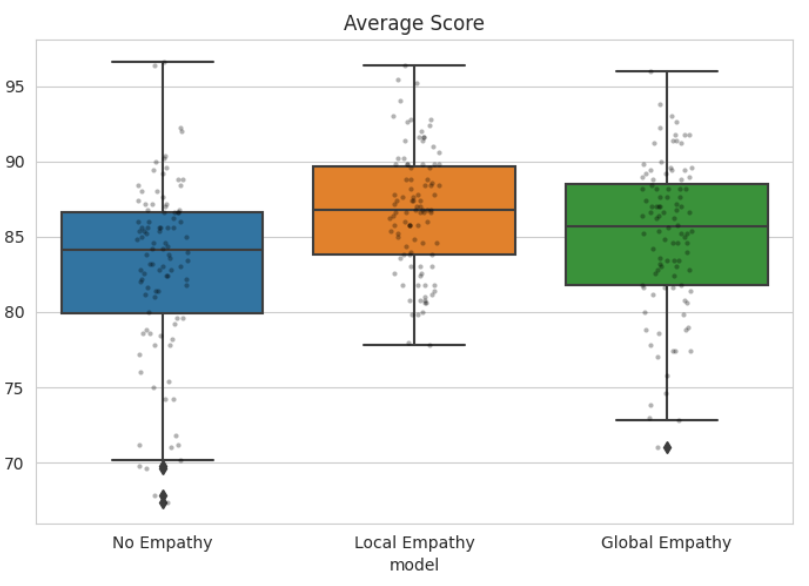 | 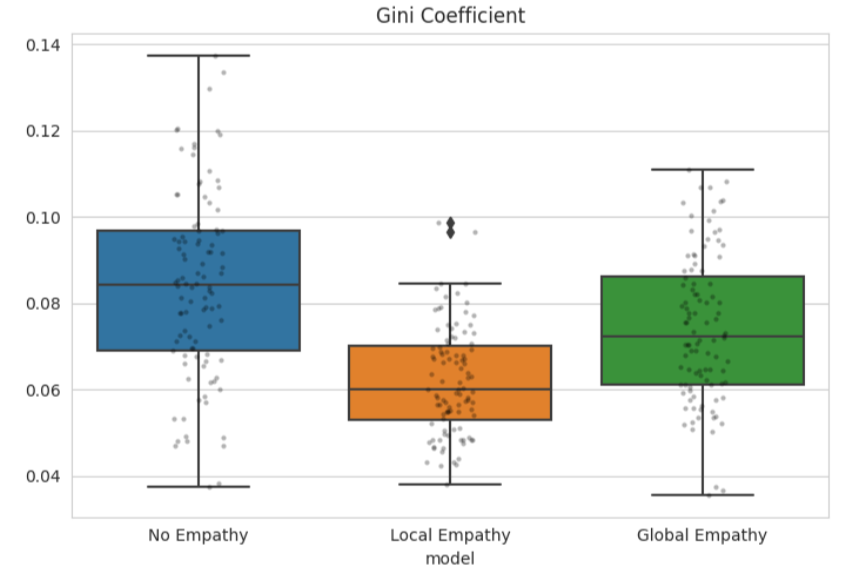 |
Both empathy variants outperform the baseline, but local empathy consistently dominates global empathy in both average reward and equality.
Conclusion
This experiment shows that engineering empathy into reward functions does not guarantee prosocial behavior.
Instead, agents learn to manipulate the conditions under which empathy is rewarded, cooperating only as long as it serves their long-term objective—and defecting once it no longer does.
This is a concrete illustration of Goodhart’s Law:
When a measure becomes a target, it ceases to be a good measure.
In the context of prosocial AI, this serves as a cautionary tale: well-intentioned reward shaping can be systematically exploited, leading to behaviors that look moral on the surface but remain fundamentally self-interested.