Deep CFR: When Regret Meets Neural Networks
A hands-on implementation of Deep Counterfactual Regret Minimization.

Introduction
Have you ever wondered how computers learn to play poker?
Most modern poker-playing agents rely on Counterfactual Regret Minimization (CFR) — a foundational algorithm from game theory that is provably convergent to a Nash equilibrium in two-player zero-sum imperfect-information games, such as poker. CFR can also be extended to multiplayer settings.
However, classical CFR requires storing values for every infoset, which quickly becomes infeasible for large games. This is where Deep CFR comes in.
In this post, I walk through a from-scratch implementation of Deep CFR, based on the paper:
Brown & Sandholm (2019) — Deep Counterfactual Regret Minimization https://arxiv.org/abs/1811.00164
The full source code is available here: 👉 https://github.com/mahdiiii04/DeepCFR
Before diving into Deep CFR itself, we start with the experimental setup: Kuhn Poker.
1. Experimental Setup: Kuhn Poker
Kuhn Poker is one of the simplest poker games, making it ideal for studying imperfect-information algorithms.
- 2 players
- 3 cards: King (2), Queen (1), Jack (0)
- Each player antes 1 chip
- One betting round
Game Flow
- Cards are dealt uniformly at random.
- Player 0 can check (
c) or bet (b). - Depending on the history, players may call (
c), bet (b), or fold (f). - If no one folds, the higher card wins the pot.
Below is the full game tree (first-level infosets highlighted for clarity):
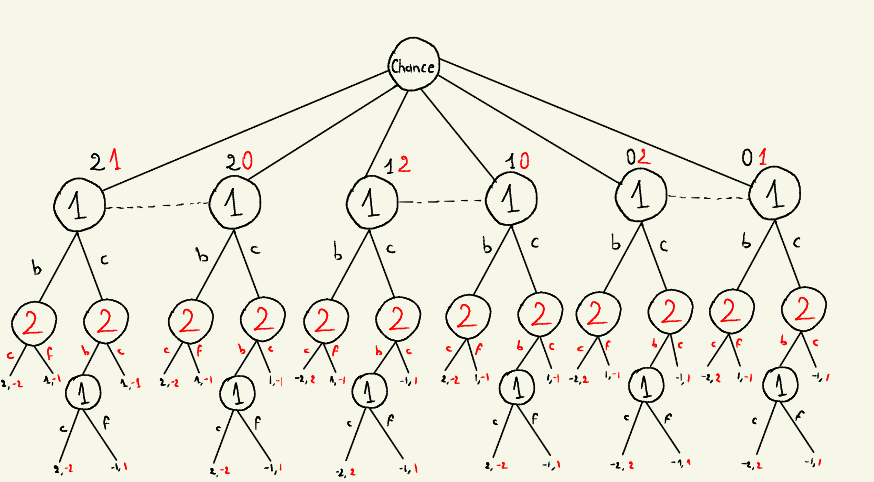
2. Implementing the Game Tree (kuhn_state.py)
The KuhnState class represents a node in the game tree.
1
2
3
4
5
6
class KuhnState:
def __init__(self, cards, history="", bets=(1, 1), player=0):
self.cards = cards
self.history = history
self.bets = list(bets)
self.player = player
cards:[player0_card, player1_card]history: string of past actions (e.g."cb")bets: current contribution of each playerplayer: whose turn it is (0 or 1)
Terminal States
1
2
def is_terminal(self):
return self.history in ["cc", "bc", "cbc", "bf", "cbf"]
A state is terminal if the betting sequence has concluded.
Payoff Function
1
2
3
4
5
6
7
8
def payoff(self):
pot = sum(self.bets)
if self.history.endswith("f"):
winner = 1 - self.player
else:
winner = 0 if self.cards[0] > self.cards[1] else 1
return pot - self.bets[winner] if winner == 0 else - (pot - self.bets[1])
This function returns the payoff from Player 0’s perspective:
- Positive → Player 0 gains
- Negative → Player 0 loses
Since Kuhn Poker is zero-sum, Player 1’s payoff is simply the negative of this value.
Legal Actions
1
2
3
4
5
6
7
8
def legal_actions(self):
if self.history == "":
return ["c", "b"]
if self.history == "c":
return ["c", "b"]
if self.history in ["b", "cb"]:
return ["f", "c"]
return []
State Transition
1
2
3
4
5
6
7
8
9
10
11
def next_state(self, action):
new = copy.deepcopy(self)
new.history += action
if action in ["b", "c"] and self.history in ["b", "cb"]:
new.bets[self.player] += 1
elif action == "b":
new.bets[self.player] += 1
new.player = 1 - self.player
return new
Infoset Representation
1
2
def infoset(self):
return self.cards[self.player], self.history
An infoset is defined by:
- The player’s private card
- The public betting history
3. Counterfactual Regret Minimization (CFR)
At the core of CFR is a simple question:
“What would have happened if I had played a different action at this infoset?”
Cumulative Regret
\[R_i^T(I, a) = \sum_{t=1}^{T} r_i^t(I, a)\]Instantaneous Regret
\[r_i^t(I, a) = v_i(\sigma^t_{I \rightarrow a}, I) - v_i(\sigma^t, I)\]Where:
- $v_i(\sigma^t_{I \rightarrow a}, I)$ is the counterfactual value if action $a$ is forced
- $v_i(\sigma^t, I)$ is the value under the current strategy
Regret Matching
Regrets are converted into a strategy via Regret Matching:
\[\sigma(I, a) = \begin{cases} \dfrac{R_i^+(I, a)}{\sum_{a'} R_i^+(I, a')} & \text{if } \sum_{a'} R_i^+(I, a') > 0 \\ \dfrac{1}{|A(I)|} & \text{otherwise} \end{cases}\]with:
\[R_i^+(I, a) = \max\{ R_i(I, a), 0 \}\]Average Strategy
The strategy that converges to Nash equilibrium is the average strategy:
\[\hat{\sigma}_i(I, a) = \frac{\sum_{t=1}^{T} \pi^t(I)\,\sigma_i^t(I, a)} {\sum_{t=1}^{T} \pi^t(I)}\]4. Deep CFR
Deep CFR replaces tabular storage with neural networks.
Networks
1
2
self.regret_net = RegretNet()
self.policy_net = PolicyNet()
Regret Network approximates cumulative regrets: \(R_\theta(I) \approx R_i^T(I)\)
Policy Network approximates the average strategy: \(P_\theta(I) \approx \hat{\sigma}_i(I)\)
Regret Matching via Network
1
2
3
4
5
6
7
def regret_matching(self, x, legal_actions):
with torch.no_grad():
regrets = self.regret_net(x)[:len(legal_actions)]
regrets = torch.clamp(regrets, min=0)
if regrets.sum() > 0:
return regrets / regrets.sum()
return torch.ones(len(legal_actions)) / len(legal_actions)
Tree Traversal
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def traverse(self, state):
if state.is_terminal():
return state.payoff()
card, history = state.infoset()
x = encode_infoset(card, history)
actions = state.legal_actions()
strategy = self.regret_matching(x, actions)
utils = torch.zeros(len(actions))
for i, a in enumerate(actions):
utils[i] = self.traverse(state.next_state(a))
node_util = (strategy * utils).sum()
regrets = utils - node_util
self.regret_buffer.append((x, regrets.detach()))
self.policy_buffer.append((x, strategy.detach()))
return node_util
This traversal:
- Computes counterfactual utilities
- Stores training targets for both networks
- Propagates expected values upward

Training Loop
1
2
3
4
5
6
7
8
9
10
def train(self, iterations=2000):
for _ in range(iterations):
cards = random.sample([0, 1, 2], 2)
self.traverse(KuhnState(cards))
self.train_net(self.regret_net, self.regret_buffer, self.r_opt)
self.train_net(self.policy_net, self.policy_buffer, self.p_opt)
self.regret_buffer.clear()
self.policy_buffer.clear()
Each iteration:
- Samples a random deal
- Traverses the game tree once
- Trains both networks
- Clears buffers
5. Results
After 20,000 training iterations, the learned strategy achieves:
Winning Rates
1
2
3
After 10000 games:
Player 0 wins: 4962 (0.496)
Player 1 wins: 5038 (0.504)
This is exactly what we expect at a Nash equilibrium in a symmetric zero-sum game. The small difference is due to stochastic sampling.
Conclusion
Although Kuhn Poker is simple, it captures the essence of imperfect information. Deep CFR scales this idea to massive games like No-Limit Texas Hold’em, where it has achieved superhuman performance.
This project demonstrates how game theory, recursion, and deep learning come together in modern AI systems.